Install NVIDIA CUDA Toolkit 12.1 on Fedora 38/37
Table of Contents
![]()
This is guide, howto install NVIDIA CUDA Toolkit 12.1 on Fedora 38/37. I assume here that you have installed NVIDIA drivers successfully using my earlier Fedora NVIDIA Drivers Install Guide. You will need NVIDIA 530.xx drivers. As always remember backup important files before doing anything!
Check video version of guide:
1. Install NVIDIA CUDA Toolkit 12.1 on Fedora 38/37⌗
1.1 Build and Install GCC 12.2⌗
Check guide howto build and install GCC 12 on Fedora 38.
1.2 Install NVIDIA Drivers >= 530.xx⌗
Check guide howto install NVIDIA Drivers 530.xx on Fedora 38.
1.3 Download NVIDIA CUDA Toolkit 12.1.1⌗
Download NVIDIA CUDA Toolkit 12.1.1 runfile (local) from official NVIDIA CUDA Toolkit download page. Only Fedora 37 version available, but it works on Fedora 38 too.
cd ~/Downloads
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_530.30.02_linux.run
1.4 Make NVIDIA CUDA installer executable⌗
chmod +x cuda_12.1.1*.run
1.5 Change root user⌗
su -
## OR ##
sudo -i
1.6 Make sure that you system is up-to-date and you are running latest kernel⌗
dnf update
After possible kernel update, you should reboot your system and boot using latest kernel:
reboot
1.7 Install needed dependencies⌗
This guide needs following, some NVIDIA CUDA examples might need something else.
dnf install gcc-c++ mesa-libGLU-devel libX11-devel libXi-devel libXmu-devel git
## Dependencies for 2_Graphics examples ##
dnf install freeglut freeglut-devel
1.8 Run NVIDIA CUDA Binary and Install NVIDIA CUDA 12.1.1⌗
/home/<username>/Downdloads/cuda_12.1.1_530.30.02_linux.run
## OR full path / full file name ##
./cuda_12.1.1_530.30.02_linux.run
/path/to/cuda_12.1.1_530.30.02_linux.run
Accept NVIDIA CUDA 12.1.1 License Agreement⌗
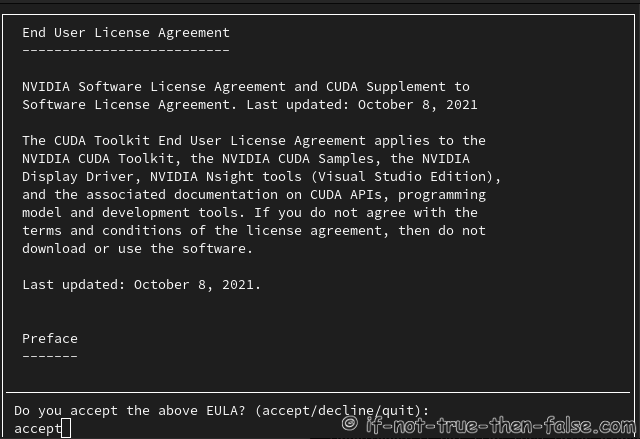
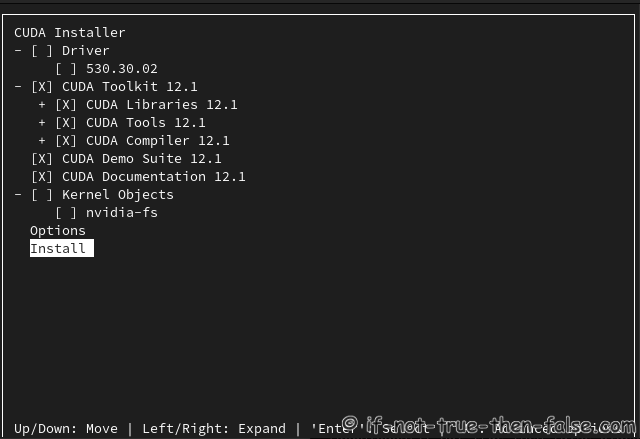
Install NVIDIA CUDA, but uncheck NVIDIA Drivers⌗
You can move here using arrows (Up/Down: Move, Left/Right: Expand, Enter/Space: Select and ‘A’: for Advanced Options)
Clone CUDA Samples from NVIDIA git repo⌗
Run following as normal user.
cd ~
git clone https://github.com/NVIDIA/cuda-samples.git
1.9 Post Installation Tasks⌗
Make sure that PATH includes /usr/local/cuda-12.1/bin and LD_LIBRARY_PATH includes /usr/local/cuda-12.1/lib64. You can of course do this per user or use some other method, but here is one method to do this. Run following command (copy & paste all lines to console) to create /etc/profile.d/cuda.sh file:
cat <<EOF >> /etc/profile.d/cuda.sh
PATH=/usr/local/cuda-12.1/bin:\$PATH
case ":\${LD_LIBRARY_PATH}:" in
*:"/usr/local/cuda-12.1/lib64":*)
;;
*)
if [ -z "\${LD_LIBRARY_PATH}" ] ; then
LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64
else
LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:\$LD_LIBRARY_PATH
fi
esac
export PATH LD_LIBRARY_PATH
EOF
Then logout/login (simply close terminal and open it again). Now as normal user and root you should see something like (depends on your system):
[user@localhost ~]$ echo $PATH
/usr/local/cuda-12.1/bin:/usr/share/Modules/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/home/user/.local/bin:/home/user/bin
[user@localhost ~]$ echo $LD_LIBRARY_PATH
/usr/local/cuda-12.1/lib64
[user@localhost ~]$
1.10 Test Your Installation, Compile and Run deviceQuery⌗
As a normal user:
cd /home/<username>/cuda-samples/Samples/1_Utilities/deviceQuery
make HOST_COMPILER="gcc-12.2 -lstdc++ -lm"
/usr/local/cuda/bin/nvcc -ccbin g++ -I../../common/inc -m64 --threads 0 --std=c++11 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_80,code=sm_80 -gencode arch=compute_86,code=sm_86 -gencode arch=compute_86,code=compute_86 -o deviceQuery.o -c deviceQuery.cpp
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
/usr/local/cuda/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_80,code=sm_80 -gencode arch=compute_86,code=sm_86 -gencode arch=compute_86,code=compute_86 -o deviceQuery deviceQuery.o
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
mkdir -p ../../bin/x86_64/linux/release
cp deviceQuery ../../bin/x86_64/linux/release
./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 2060"
CUDA Driver Version / Runtime Version 12.1 / 12.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 5927 MBytes (6214451200 bytes)
(030) Multiprocessors, (064) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1695 MHz (1.70 GHz)
Memory Clock rate: 7001 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.1, CUDA Runtime Version = 12.1, NumDevs = 1
Result = PASS
Thats all!
Please let me know if you have any problems!